1. 프로세스
[ 공부하기 전 나 ]
프로세스? 실행중인거!
1) 프로그램과 프로세스의 차이
생명이 있냐, 없냐
프로그램은 보조기억장치(SSD,하드디스크)에 존재하는, 실행되기를 기다리는 코드와 정적인 데이터의 묶음이다.
요것이 메모리에 적재되면 생명이 있는 '프로세스'가 된다.
즉, 실행파일이 메모리에 적재될 때 프로그램은 프로세스가 된다라고 할 수 있다.
프로세스란 쉽게 말해 프로그램 실행 그 자체를 의미한다.
2) 동시 실행의 착각
컴퓨터에서 프로세스가 동시에 실행된다는 건 당연하지 않은 일.
하나의 CPU(프로세서) 는 한 순간에 하나의 프로세스만 실행할 수 있기 때문이다.
그러면 프로세스가 동시에 실행된다라고 말할 수 없는거 아닌가?
맞다.
물 속에서 헤엄치는 오리를 생각해보자.

둥둥 떠있는 오리는 사실 물 속에서 엄청나게 발을 휘저으며 헤엄친다.
프로세스가 동시에 실행될 수 있는 건 운영체제가 엄청난 속도로 CPU가 실행할 프로세스를 교체하고 있기 때문이다.
눈 깜박할 사이에 이 교체가 수십번~수천번 일어나기 때문에 사람은 동시에 여러개의 프로세스가 실행되고 있다고 느끼는 것이다.
그럼 도대체 운영체제는 어떻게 이렇게 빨리 휘리릭 프로세스 교체를 할 수 있는 것일까?
프로세스의 구성 관리에 대해 알아보면 해답이 나올지도 모르겠다.
3) 프로세스 구성
프로세스에 대한 정보는 프로세스 제어블록(PCB,Process Control Block) 이라고 부르는 자료구조에 저장이 된다.
이 PCB 에는 다음과 같은 정보가 담겨있다. ( 운영체제가 프로세스를 관리하기 위해 필요한 정보를 저장함 )
|
PID
|
운영체제가 각 프로세스를 식별하기 위해 부여된 식별번호
|
|
프로세스 상태
|
진행중인 상태인지, 대기중인 상태인지, 종료된 상태인지
|
|
프로그램 카운터
|
CPU가 다음 실행할 명령어의 주소를 담고 있는 레지스터이다.
프로그램의 순차적 흐름을 위해 필요하다고 한다... |
|
스케줄링 우선순위
|
운영체제가 CPU 에서 실행될 여러 개의 프로세스 순서를 정해주는 것을 스케줄링 이라고 한다.
스케줄링에서 우선순위가 높으면 먼저 실행될 수 있는데 이를 스케줄링 우선순위라고 한다. |
|
권한
|
프로세스가 접근할 수 있는 자원을 결정하는 정보이다.
프로세스마다 어디까지 접근할 수 있는지에 대한 권한이다. |
|
프로세스의 부모와 자식 프로세스
|
최초로 생성되는 init 프로세스를 제외하고 모든 프로세스는 부모 프로세스를 복제하여 생성되고 이 계층관계는 트리를 형성한다.
그래서 각 프로세스는 자식프로세스와 부모프로세스에 대한 정보를 가지고 있다. |
|
프로세스의 데이터와 명령어가 있는 메모리 위치를 가리키는 포인터
|
프로그램에 대한 정보는 프로세스가 메모리에 가지는 자신만의 주소 공간에 저장된다.
프로세스는 프로그램의 실행이기 때문에 실행하기 위해서는 프로그램 주소에 대한 정보가 필요한 것이다. |
|
실행문맥
|
마지막에 실행된 프로세스의 레지스터 내용을 담고 있다.
운영체제에 의해 교체되었다가 다시 자신의 차례가 되어 실행될 때 중단된 적 없고 마치 연속적으로 실행된 것처럼 보이기 위해 해당 레지스터 정보를 가지고 있다. |
4) 프로세스 관리
- 프로세스 상태
- New: 프로그램이 메인 메모리에 할당된다.
- Ready: 할당된 프로그램이 초기화와 같은 작업을 통해 실행되기 위한 모든 준비를 마친다.
- Running: CPU가 해당 프로세스를 실행한다.
- Waiting: 프로세스가 끝나지 않은 시점에서 I/O로 인해 CPU를 사용하지 않고 다른 작업을 한다. (해당 작업이 끝나면 다시 CPU에 의해 실행되기 위해 ready 상태로 돌아가야 한다.)
- Terminated: 프로세스가 완전히 종료된다.

running에서 ready로 변할 때는 time sharing system(시분할,각 사용자들에게 컴퓨터 자원을 시간적으로 분할)에서 해당 프로세스가 CPU시간을 모두 소진하였을 때 인터럽트에 의해 강제로 ready상태로 변하고, CPU는 다른 프로세스를 실행시킨다.
5) 프로세스의 메모리 영역
- Code 영역
실행할 프로그램의 코드나 명령어들이 기계어 형태로 저장된 영역이다.
CPU는 코드영역에 저장된 명령어들을 하나씩 처리한다.
- Data 영역
코드에서 선언한 전역 변수와 정적 변수가 저장되는 영역이다.
프로그램이 실행되면서 할당되고 종료되면서 소멸한다.
- Stack 영역
함수 안에서 선언된 지역변수, 매개변수, 리터값등이 저장된다.
함수 호출시 기록되고 종료되면 제거된다.
- Heap 영역
관리가 가능한 데이터 이외의 다른 형태의 데이터를 관리하기 위한 자유공간이다.
2. 스레드
스레드는 프로세스 내의 Data, Code, Heap 영역을 공유한다.
운영체제는 프로세스마다 독립된 메모리 영역을 Code/Data/Stack/Heap의 형식으로 할당한다.
각각 독립된 메모리 영역을 할당해주기 때문에 프로세스는 다른 프로세스의 변수나 자료에 접근할 수 없다.
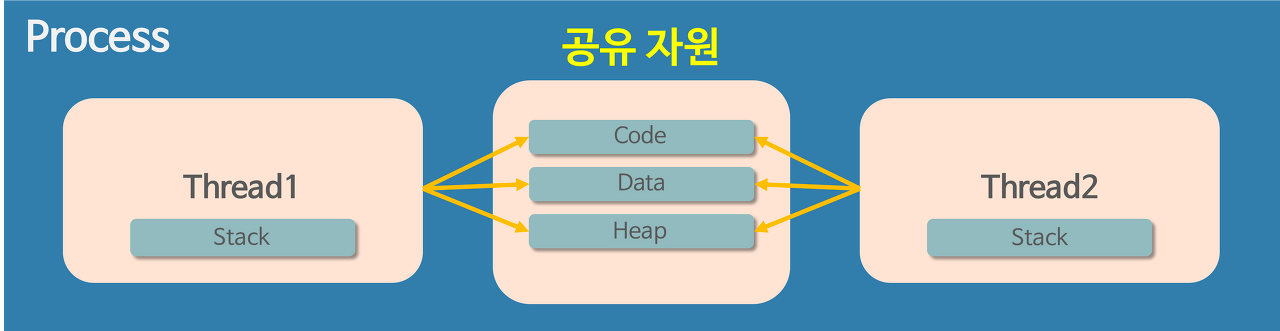
(이미지 출처 : https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html)
반면에 스레드는 메모리를 서로 공유할 수 있다.
프로세스가 할당받은 메모리 영역 내에서 Stack 형식으로 할당된 메모리 영역은 별도로 할당받고,
나머지 Code/Data/Heap 형식으로 할당된 메모리 영역을 공유한다.
따라서, 각각의 스레드는 별도의 스택을 가지고 있지만 힙 메모리는 서로 읽고 쓸 수 있게 된다.
* 단일 스레드와 다중 스레드의 차이
예) 웹서버가 여러 개의 클라이언트 요청을 받는 경우
- 단일스레드 : 한 번에 하나의 클라이언트만 서비스 할 수 있어 시간이 오래 걸린다.
그러면 매번 요청할 때마다 동일한 요청을 수행하는 별도의 프로세스를 생성하면 되지 않나?
-> But, 프로세스 생성은 많은 시간과 자원이 필요하므로 비효율적이다.
새 프로세스 할 일이 기존 프로세스 할 일과 동일하다면 굳이 ?
그. 래. 서.
기존 프로세스 안에다가 여러 개의 스레드를 만드는 것이 더 효율적이다.
🟢 멀티스레드의 장점
- Context-Switching 할 때 공유하고 있는 메모리만큼 메모리 자원을 아낄 수 있다.
- 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신 부담이 적어서 응답 시간이 빠르다.
🔴 멀티스레드의 단점
- 스레드 하나가 프로세스 내 자원을 망쳐버린다면 모든 프로세스가 종료될 수 있다.
- 자원을 공유하기 때문에 필연적으로 동기화 문제가 발생할 수 밖에 없다. 교착상태가 발생하지 않도록 주의해야 한다.
출처
https://ko.wikipedia.org/wiki/%EC%8B%9C%EB%B6%84%ED%95%A0_%EC%8B%9C%EC%8A%A4%ED%85%9C
'리눅스&네트워크' 카테고리의 다른 글
| [네트워크 보안] ICMP 와 브로드캐스트 개념 이해 (1) | 2025.07.08 |
|---|---|
| 마운트 (0) | 2022.07.20 |