- 자신의 OS 정보 확인
[root@localhost ~]$ hostnamectl
Static hostname: localhost
...
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-1160.el7.x86_64
Architecture: x86-64
- 하단 링크 연결하여 오라클 클라이언트 버전에 맞춰 Basic 과 Sqlplus 의 RPM 파일을 다운로드 한다.
https://www.oracle.com/database/technologies/instant-client/linux-x86-64-downloads.html
★ 여기서 주의 ★
내가 연결하려는 원격 Oracle 버전을 확인하자!
해당 버전에 맞는 클라이언트 버전을 설치해줘야 한다.!!
- root 계정으로 rpm 파일을 설치한다. (basic 먼저 설치한 후, sqlplus 설치한다.)
$ yum install -y oracle-instantclient-basic-10.2.0.5-1.x86_64.rpm
$ yum install -y oracle-instantclient-sqlplus-10.2.0.5-1.x86_64.rpm
ERROR: Failed dependences: libaio is needed by oracle_instantclient10.2.0.5.-1.x86_64
에러 경우 의존성 라이브러리 파일이 없어서 발생하는 것이므로 아래 라이브러리 설치하면 된다.
$ yum install -y libaio
- ORACLE_HOME, TNS_ADMIN 환경변수를 위한 설정파일을 추가한다.
$ vi /etc/profile.d/oracle.sh
export ORACLE_HOME=/usr/lib/oracle/10.2.0.5/client64
export TNS_ADMIN=/usr/lib/oracle/10.2.0.5/client64/bin
- .bash_profile 하단에 ORACLE_HOME, TNS_ADMIN, PATH 설정 추가 후 .bash_profile 을 적용한다.
vi ~/.bash_profile
export ORACLE_HOME=/usr/lib/oracle/10.2.0.5/client64
export TNS_ADMIN=/usr/lib/oracle/10.2.0.5/client64/bin
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
export PATH=$ORACLE_HOME/bin:$PATH
export NLS_LANG=KOREAN_KOREA.AL32UTF8
설정 후, 바로 적용을 위해 source 명령어를 사용한다.
$ source ~/.bash_profile정상적으로 적용된 것을 확인하려면 env 명령어를 사용해보자.
$ env- oracle instant client 에서 oracle server 로 접속하기 위해서 tnsnames.ora 를 설정한다.
TNS(Transparent Network Substrate) 는 오라클에서 사용하는 네트워크 기술이다.
Client/Server 또는 Server/Server 간에도 Data 전송을 가능하게 해주는 기술이다.
★ tnsnames.ora 파일은 오라클 클라이언트 측에서 오라클 서버로 접속할 때 필요한 프로토콜 및 포트번호, 서버주소, 인스턴스 등을 설정해주는 파일이다.
★tnsnames.ora 파일은 우리가 TNS_ADMIN 경로로 잡아둔 곳 아래에 위치해 있어야 한다.
나는 TNS_ADMIN 경로를 /usr/lib/oracle/10.2.0.5/client64/bin 으로 잡았기에, 해당 폴더 아래에 tnsnames.ora 파일을 두었다.
원하는 TNS 이름(별명) =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 아이피주소)(PORT = 1521)
예제)
ORA_DB(별명)=
(DESCRIPTION =
(ADDRESS =
(PROTOCOL = TCP)
(HOST = 아이피주소)
(PORT = 1521)
)
(CONNECT_DATA =
(SID = 접속할 SID)
)
)
- oracle client 에서 oracle server 로 sqlplus 명령어로 접속해보자!! (root 계정으로 접속해야 한다!!)
$ sqlplus id/passwd@별명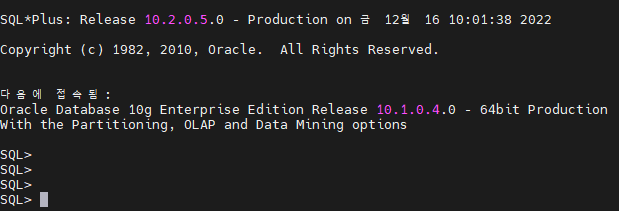
★ 여기서 주의 ★
아래와 같은 에러를 마주쳤다면, 내가 연결하려는 원격 Oracle 버전을 확인하자!
해당 버전에 맞는 클라이언트 버전을 설치해줘야 한다.!!

: 내가 연결하려는 오라클 DB 버전이 10 버전대였는데, 서버에 붙으려서 클라이언트 버전은 그보다 높은 12버전이라 발생한 문제였다.
출처
'리눅스&네트워크' 카테고리의 다른 글
| [운영체제] 프로세스와 스레드 (0) | 2022.12.11 |
|---|---|
| 마운트 (0) | 2022.07.20 |